Amodal Instance Segmentation (AIS) endeavors to accurately deduce complete object shapes that are partially or fully occluded.
However, the inherent ill-posed nature of single-view datasets poses challenges in determining occluded shapes.
A multi-view framework may help alleviate this problem, as humans often adjust their perspective when encountering occluded objects.
At present, this approach has not yet been explored by existing methods and datasets.
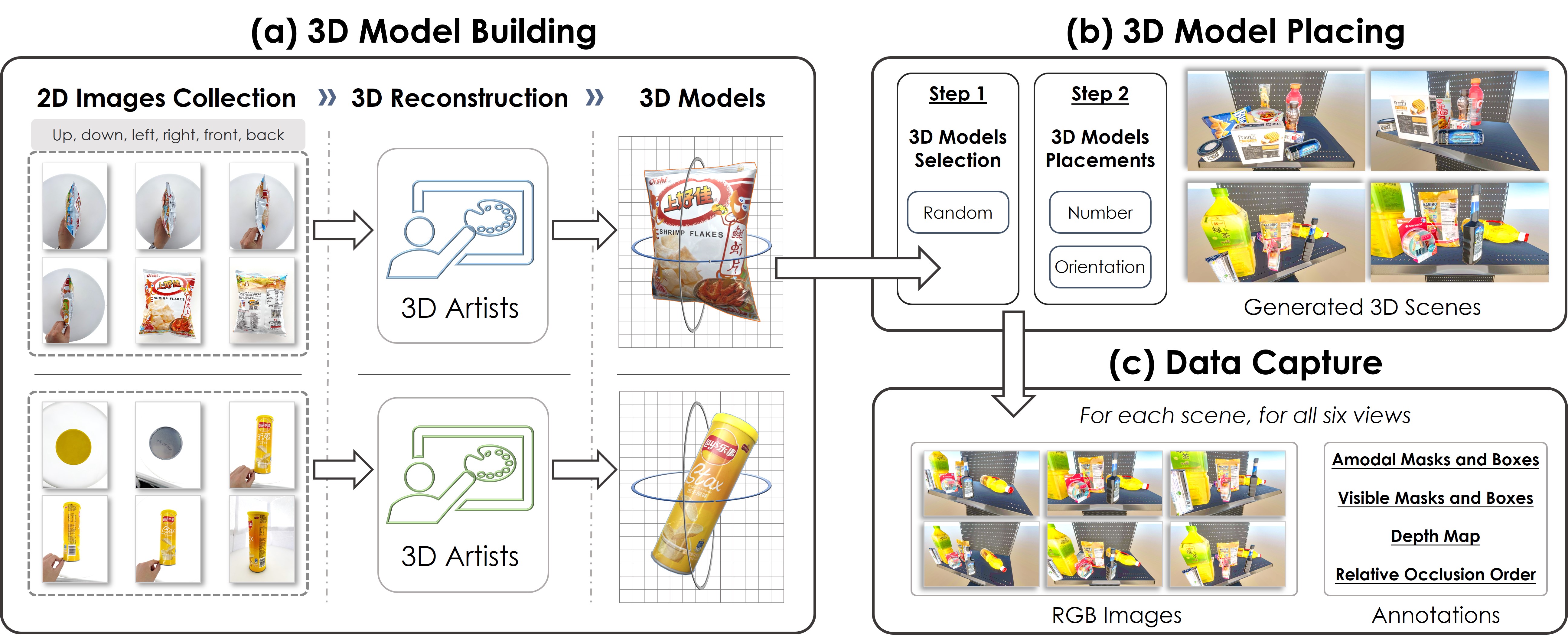
To bridge this gap, we propose a new task called Multi-view Amodal Instance Segmentation (MAIS) and introduce the MUVA dataset,
the first MUlti-View AIS dataset that takes the shopping scenario as instantiation.
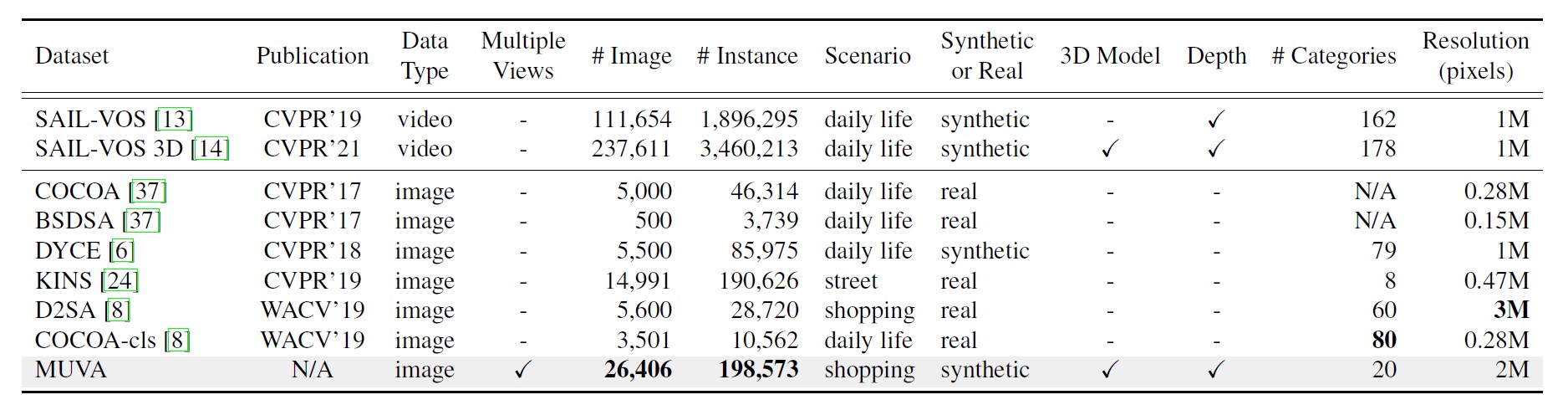
MUVA provides comprehensive annotations, including multi-view amodal/visible segmentation masks, 3D models, and depth maps, making it the largest image-level AIS dataset in terms of both the number of images and instances. Additionally, we propose a new method for aggregating representative features across different instances and views, which demonstrates promising results in accurately predicting occluded objects from one viewpoint by leveraging information from other viewpoints. Besides, we also demonstrate that MUVA can benefit the AIS task in real-world scenarios.